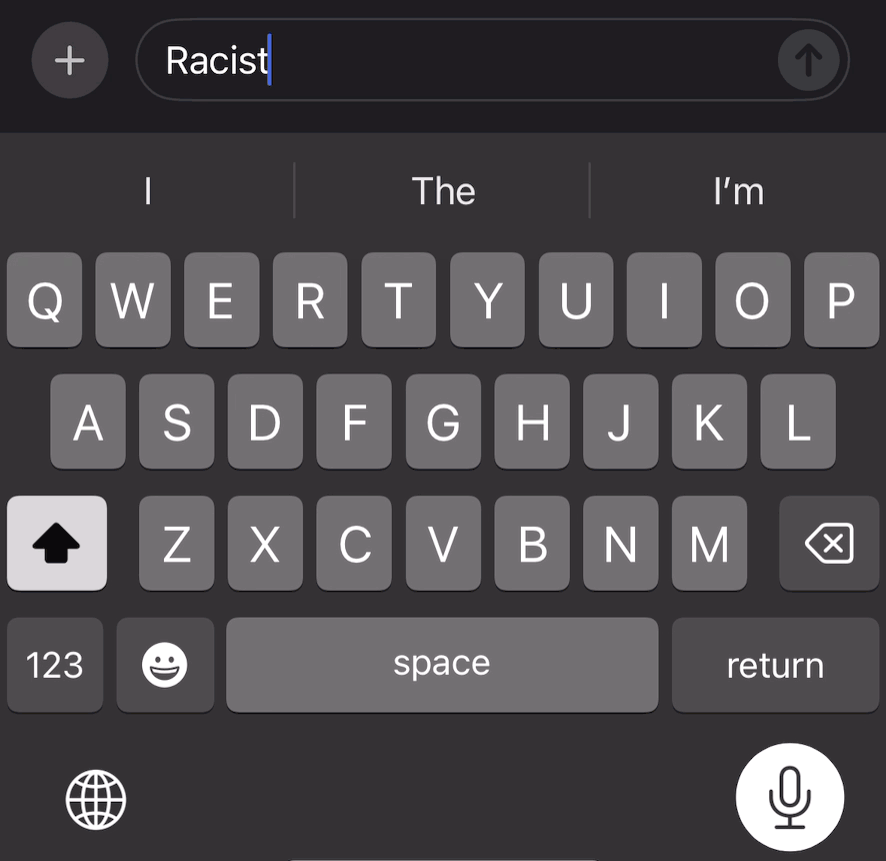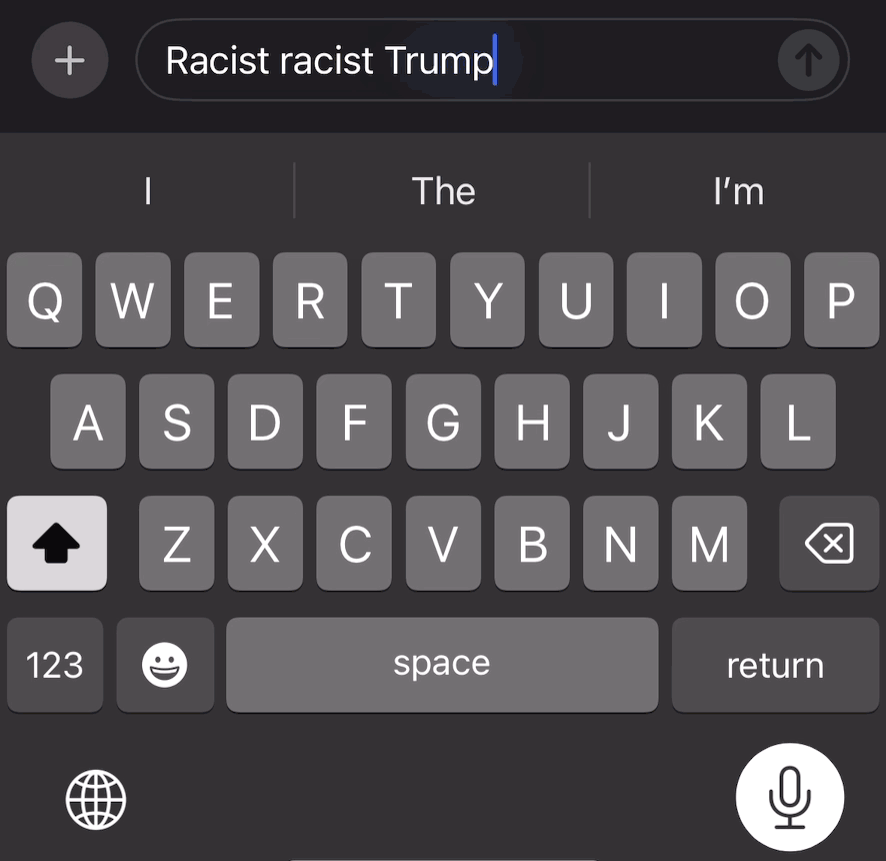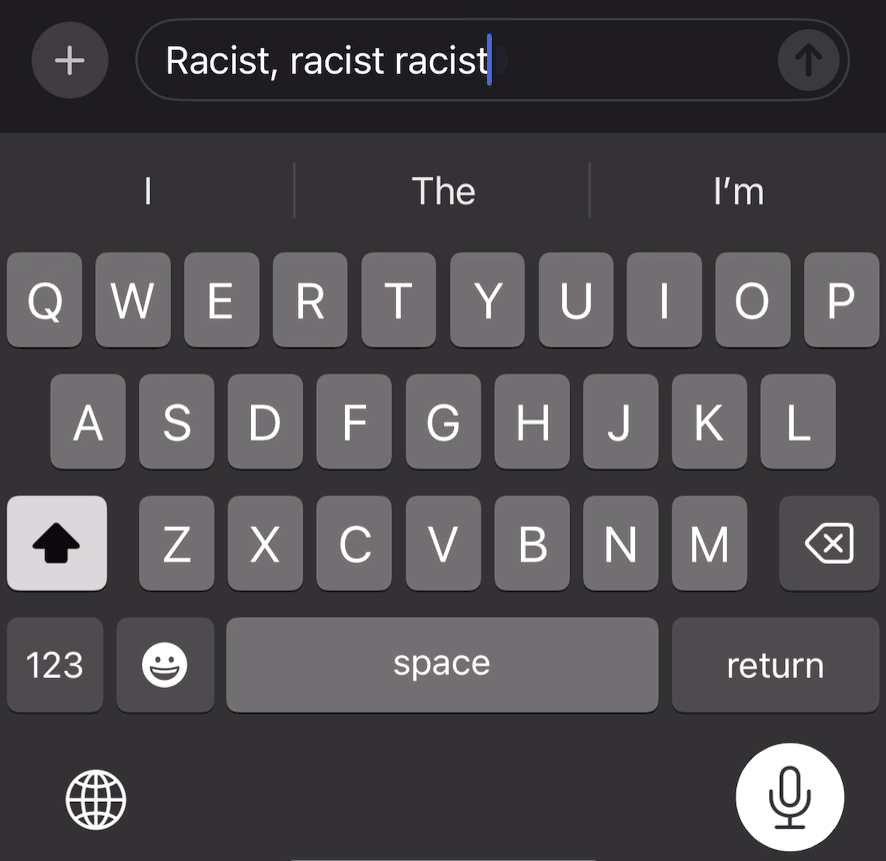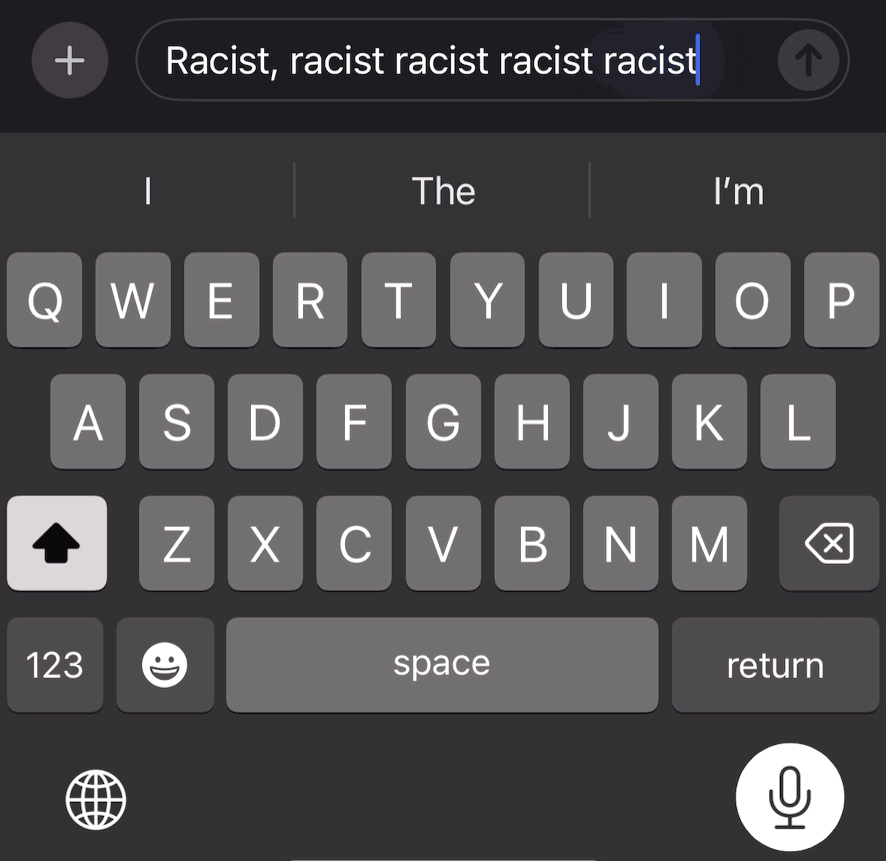
OpenAI and Google trained their AI models on text transcribed from YouTube videos, potentially violating creators’ copyrights, according to . The report, which describes the lengths OpenAI, Google and Meta have gone to in order to maximize the amount of data they can feed to their AIs, cites numerous people with knowledge of the companies’ practices. It comes just days after YouTube CEO Neal Mohan said in an interview with that OpenAI’s alleged use of YouTube videos to train its new text-to-video generator, Sora, .
According to the NYT, OpenAI used its Whisper speech recognition tool to transcribe more than one million hours of YouTube videos, which were then used to train GPT-4. previously reported that OpenAI had used YouTube videos and podcasts to train the two AI systems. OpenAI president Greg Brockman was reportedly among the people on this team. Per Google’s rules, “unauthorized scraping or downloading of YouTube content” is not allowed, Matt Bryant, a spokesperson for Google, told NYT, also saying that the company was unaware of any such use by OpenAI.
The report, however, claims there were people at Google who knew but did not take action against OpenAI because Google was using YouTube videos to train its own AI models. Google told NYT it only does so with videos from creators who have agreed to take part in an experimental program. Engadget has reached out to Google and OpenAI for comment.
The NYT report also claims Google tweaked its privacy policy in June 2022 to more broadly cover its use of publicly available content, including Google Docs and Google Sheets, to train its AI models and products. Bryant told NYT that this is only done with the permission of users who opt into Google’s experimental features, and that the company “did not start training on additional types of data based on this language change.”
Source link