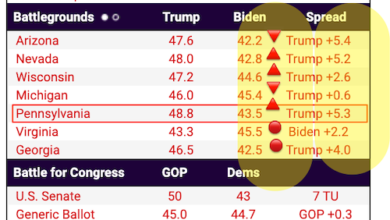
Your humble blogger has taken a gander through a new IMF paper on the anticipated economic, and in particular, labor market, impact of the incorporation of AI into commercial and government operations. As the business press has widely reported, the IMF anticipates that 60% of advanced economy jobs could be “impacted” by AI, with the guesstimmate that half would see productivity gains, and the other half would see AI replacing their work in part or in whole, resulting in job losses. I do not understand why this outcome would not also be true for roles seeing productivity enhancement, since more productivity => more output from workers => not as many workers needed.
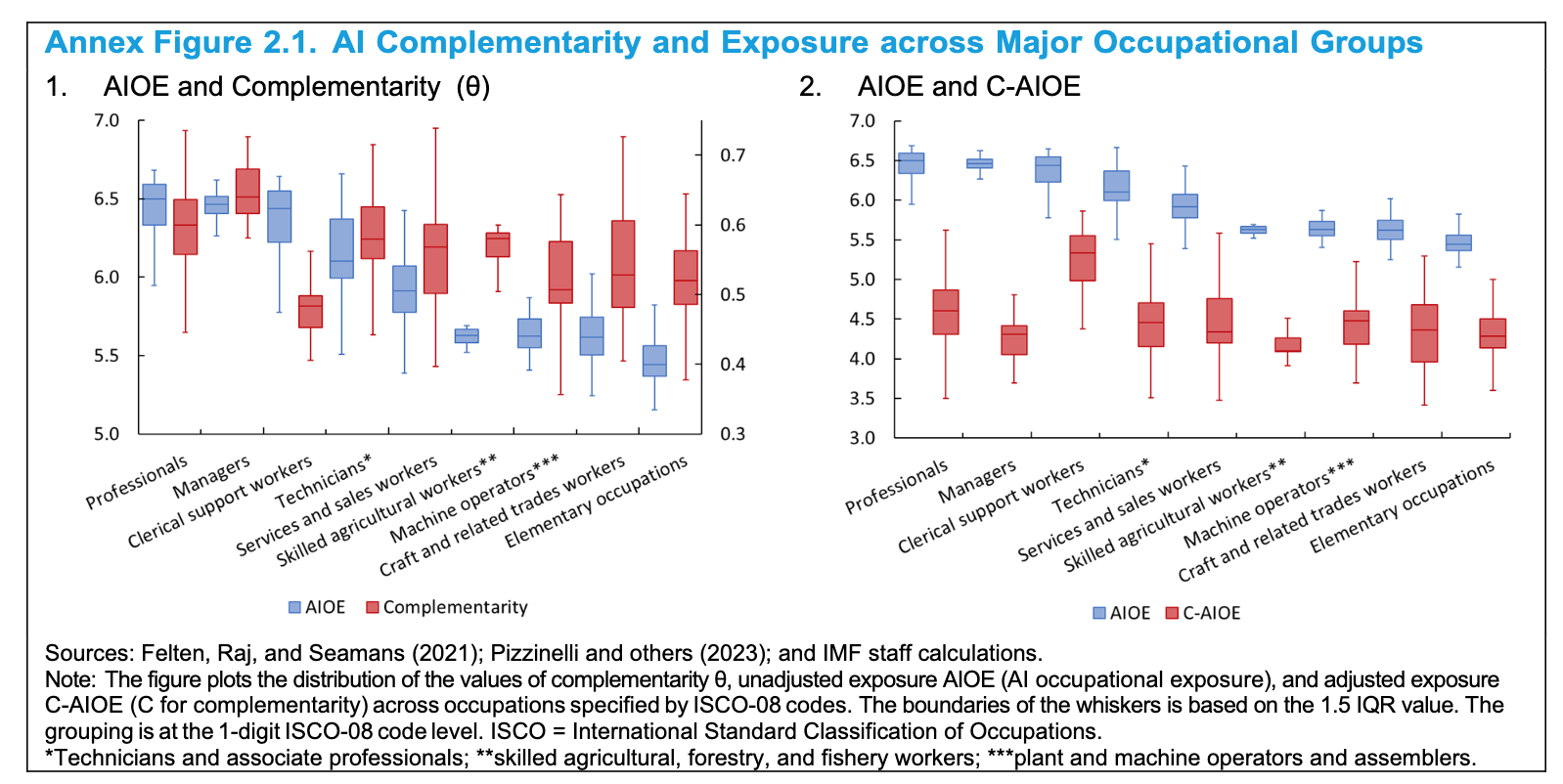
In any event, this IMF article is not pathbreaking, consistent with the fact that it appears to be a review of existing literature plus some analyses that built on key papers. Note also that the job categories are at a pretty high level of abstraction:
Mind you, I am not disputing the IMF forecast. It may very well prove to be extremely accurate.
What does nag at me in this paper, and many other discussions of the future of AI, is the failure to give adequate consideration to some of the impediments to adoption. Let’s start with:
Difficulties in creating robust enough training sets. Remember self-driving trucks and cars? This technology was hyped as destined to be widely adopted, at least in ride-share vehicles, already. Had that happened, it would have had a big impact on employment. Driving a truck or a taxi is a big source of work for the lesser educated, particularly men (and particularly for ex-cons who have great difficulty in landing regular paid jobs). According to altLine, citing the Bureau of Labor Statistics, truck driving was the single biggest full-time job category for men, accounting for 4% of the total in 2020. In 2022, American Trucking estimated the total number of truckers (including women) at 3.5 million. For reference, Data USA puts the total number of taxi drivers in 2021 at 284,000, plus 1.7 million rideshare drivers in the US, although they are not all full time.
A December Guardian piece explained why driverless cars are now “on the road to nowhere.” The entire article is worth reading, with this a key section:
The tech companies have constantly underestimated the sheer difficulty of matching, let alone bettering, human driving skills. This is where the technology has failed to deliver. Artificial intelligence is a fancy name for the much less sexy-sounding “machine learning”, and involves “teaching” the computer to interpret what is happening in the very complex road environment. The trouble is there are an enormous number of potential use cases, ranging from the much-used example of a camel wandering down Main Street to a simple rock in the road, which may or may not just be a paper bag. Humans are exceptionally good at instantly assessing these risks, but if a computer has not been told about camels it will not know how to respond. It was the plastic bags hanging on [pedestrian Elaine] Herzberg’s bike that confused the car’s computer for a fatal six seconds, according to the subsequent analysis.
A simple way to think of the problem is that the situations the AI needs to address are too large and divergent to create remotely adequate training sets.
Liability. Liability for damage done by an algo is another impediment to adoption. If you read the Guardian story about self-driving cars, you’ll see that both Uber and GM went hard into reverse after accidents. At least they didn’t go into Ford Pinto mode, deeming a certain level of death and disfigurement to be acceptable given potential profits.
One has to wonder if health insurers will find the use of AI in medical practice to be acceptable. If, say, an algo gives a false negative on a cancer diagnostic screen (say an image), who is liable? I doubt insurers will let doctors or hospitals try to blame Microsoft or whoever the AI supplier is (and they are sure to have clauses that severely limit their exposure). On top of that, it would be arguably a breach of professional responsibility to outsource judgement to an algo. Plus the medical practitioner should want any AI provider to have posted a bond or otherwise have enough demonstrable financial heft to absorb any damages.
I can easily see not only health insurers restricting the use of AI (they do not want to have to chase more parties for payment in the case of malpractice or Shit Happens than they do now) but also professional liability insurers, like writer of medical malpractice and professional liability policies for lawyers.
Energy use. The energy costa of AI are likely to result in curbs on its use, either by end-user taxes, overall computing cost taxes or the impact of higher energy prices. From Scientific American last October:
Researchers have been raising general alarms about AI’s hefty energy requirements over the past few months. But a peer-reviewed analysis published this week in Joule is one of the first to quantify the demand that is quickly materializing. A continuation of the current trends in AI capacity and adoption are set to lead to NVIDIA shipping 1.5 million AI server units per year by 2027. These 1.5 million servers, running at full capacity, would consume at least 85.4 terawatt-hours of electricity annually—more than what many small countries use in a year, according to the new assessment.
Mind you, that’s only by 2027. And consider that the energy costs also are a reflection of more hardware installation. Again from the same article, quoting data scientist Alex de Vries, who came up with the 2027 energy consumption estimate:
I put one example of this in my research article: I highlighted that if you were to fully turn Google’s search engine into something like ChatGPT, and everyone used it that way—so you would have nine billion chatbot interactions instead of nine billion regular searches per day—then the energy use of Google would spike. Google would need as much power as Ireland just to run its search engine.
Now, it’s not going to happen like that because Google would also have to invest $100 billion in hardware to make that possible. And even if [the company] had the money to invest, the supply chain couldn’t deliver all those servers right away. But I still think it’s useful to illustrate that if you’re going to be using generative AI in applications [such as a search engine], that has the potential to make every online interaction much more resource-heavy.
Sabotage. Despite the IMF attempting to put something of a happy face on the AI revolution (that some will become more productive, which could mean better paid), the reality is people hate change, particularly uncertainty about job tenures and professional survival. The IMF paper casually mentioned telemarketers as a job category ripe for replacement by AI. It is not hard to imagine those who resent the replacement of often-irritating people with at least as irrigating algo testing to find ways to throw the AI into hallucinations, and if they succeed, sharing the approach. Or alternatively, finding ways to tie it up, such as with recordings that could keep it engaged for hours (since it would presumably then require more work with training sets to teach the AI when to terminate a deliberately time-sucking interaction).
Another area for potential backfires in the use of AI in security, particularly related to financial transactions. Again, the saboteur might not have to be as successful as breaking the tools so as to heist money. They could instead, as in a more sophisticated version of the “telemarketers’ revenge” seek to brick customer service or security validation processes. A half day of loss of customer access would be very damaging to a major institution.
So I would not be as certain that AI implementation will be as fast and broad-based as enthusiasts depict. Stay tuned.

Source link